




















Guest Access





Go to page : ![]() 1, 2, 3, 4
1, 2, 3, 4 ![]()
![]()
![]()
 Message [Page 3 of 4]
Message [Page 3 of 4]
Active Member
Active Member

Active Member
profile 
 149
149
 10
10
 2010-06-25
2010-06-25
 181
181

 Yea, even rpg makers do it.
Yea, even rpg makers do it.

Reala
 | ||
profile
149102010-06-25181 Yea, even rpg makers do it.Active Member
Show Signature
Active Member
Tutorial Wizardmaster
Tutorial Wizardmaster

Tutorial Wizardmaster
profile 







 679
679
230
2009-10-10
 1985-03-08
1985-03-08
 39
39
956

XAS ABS








 Having the words:
Having the words:
Eternal
Forever
Destiny
In the name of your game. Blah. So over used and clichéd.
Someone's gonna come out with a game called Eternal Destiny Forever now just to piss me off haha
calvin624
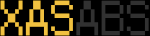 | ||
profile
6792302009-10-101985-03-0839956XAS ABS
Having the words: Eternal
Forever
Destiny
In the name of your game. Blah. So over used and clichéd.
Someone's gonna come out with a game called Eternal Destiny Forever now just to piss me off haha
Tutorial Wizardmaster
Show Signature
Tutorial Wizardmaster

ACTIVATED
ACTIVATED

ACTIVATED
profile  48
48
16
2010-03-01
83
pokemon, naruto and dragonball fangames.
shogun3
 | ||
profile
48162010-03-0183 pokemon, naruto and dragonball fangames. ACTIVATED
Show Signature
ACTIVATED
EVENTALIST
EVENTALIST

EVENTALIST
profile 







 3021
3021
908
2009-12-11
1991-04-18
33
4299

Cleverkat








noooope :p
mr_wiggles
 | ||
profile
30219082009-12-111991-04-18334299Cleverkat
calvin624 wrote:
Someone's gonna come out with a game called Eternal Destiny Forever now just to piss me off haha
noooope :p
EVENTALIST
Show Signature
EVENTALIST
Poster Mcposty
Poster Mcposty

Poster Mcposty
profile 




 1933
1933
387
2010-03-01
1994-04-13
30
1759

M
 Your rival helping you defeat a hard boss, but in a mean tone probably saying: "This doesn't change a thing".
Your rival helping you defeat a hard boss, but in a mean tone probably saying: "This doesn't change a thing".
MotionM
 | ||
profile
19333872010-03-011994-04-13301759M
Your rival helping you defeat a hard boss, but in a mean tone probably saying: "This doesn't change a thing". Poster Mcposty
Show Signature
Poster Mcposty



Tutorial Wizardmaster
Tutorial Wizardmaster
Tutorial Wizardmaster
profile
679
230
2009-10-10
1985-03-08
39
956
XAS ABS
I dunno, that sounds pretty cool haha
calvin624
| ||
profile
6792302009-10-101985-03-0839956XAS ABS
M™ wrote: Your rival helping you defeat a hard boss, but in a mean tone probably saying: "This doesn't change a thing".
I dunno, that sounds pretty cool haha
Tutorial Wizardmaster
Show Signature
Tutorial Wizardmaster
C.O.R.N.
C.O.R.N.

C.O.R.N.
profile 




 4360
4360
507
2010-01-21
1997-04-30
26
6797

Stephen
 wouldn't it be better if the rival just...died?
wouldn't it be better if the rival just...died?
BluE
 | ||
profile
43605072010-01-211997-04-30266797Stephen
wouldn't it be better if the rival just...died?C.O.R.N.
Show Signature
C.O.R.N.
Tutorial Wizardmaster
Tutorial Wizardmaster
Tutorial Wizardmaster
profile
679
230
2009-10-10
1985-03-08
39
956
XAS ABS
Or you turn on him at the end of the battle and get him unawares
calvin624
| ||
profile
6792302009-10-101985-03-0839956XAS ABS
Or you turn on him at the end of the battle and get him unawares Tutorial Wizardmaster
Show Signature
Tutorial Wizardmaster
C.O.R.N.
C.O.R.N.
C.O.R.N.
profile
4360
507
2010-01-21
1997-04-30
26
6797
Stephen
well yea. the rival becoming your friend or being even cooler at the end is boring
BluE
| ||
profile
43605072010-01-211997-04-30266797Stephen
well yea. the rival becoming your friend or being even cooler at the end is boringC.O.R.N.
Show Signature
C.O.R.N.
Active Member
Active Member
Active Member
profile 149
10
2010-06-25
181
Ok, added everything u guys said. lol uve played alot of bad games.
Reala
| ||
profile
149102010-06-25181 Ok, added everything u guys said. lol uve played alot of bad games.Active Member
Show Signature
Active Member
![]()
![]() Message [Page 3 of 4]
Message [Page 3 of 4]
Go to page : ![]() 1, 2, 3, 4
1, 2, 3, 4 ![]()






















